CSG Data Engineering & AI
and RWTH Aachen University
Cross-Sectional Group
The newly formed CSG Data Engineering & AI was created from the merger of the CSG Data Science & ML and the CSG Data Management at the beginning of 2026. The CSG combines expertise in research data management, automated data engineering, data science and machine learning to advance end-to-end research from raw data to actionable insights on HPC systems.
The CSG Data Engineering & AI brings together expertise in research data management, automated data engineering, data science and machine learning to support seamless, end-to-end research workflows on HPC systems. Its goal is to advance scalable, reproducible, and efficient data
pipelines and analytic processes. By uniting these areas of expertise, the group develops methods, tools, and workflows that accelerate research, reduce friction, and deliver insights for the broader scientific community.

Current research topics
- Automated Data Engineering with Large Language Models (Liane Vogel and Jan-Micha Bodensohn)
- The project evaluates and uses Large Language Models to automate data engineering tasks like data integration and cleaning on tabular data to reduce manual overheads.
- WikiDBs: A corpus of 100,000 real-world databases (Liane Vogel and Jan-Micha Bodensohn)
- WikiDBs is a large-scale corpus of 100k relational databases crawled from Wikidata. It enables the training of multi-table foundation models as well as the evaluation of table retrieval and integration approaches.
- Query Execution over Data Lakes (Jan-Micha Bodensohn)
- Executing SQL queries over data lakes is challenging because of the disorganized data and lack of relational schemas. Our goal is to make data lakes as easy to query as relational databases.
- Linking Research Data Management and HPC (Marcel Nellesen)
- Provide easy ways to apply for storage space similar to HPC applications
- Data Management, Access Workflows and Knowledge Graph based Metadata Management
- Data Transfers between S3 solutions and HPC nodes
- Efficient metadata management with support for automated extraction of metadata
- Connection to many other federal and national RDM initiatives (NFDI, fdm.nrw…)
- AutoML
- Federated Learning
- HPC Data Extraction (Aaron Küsters)
- Developing a robust library for analyzing, creating, and managing SLURM job in Rust (https://docs.rs/slurry/)
- Allows integration in other tools, e.g., to deploy workload on HPC
- Can extract object-centric event logs (OCEL) from HPC clusters, incorporating data from multiple perspectives, i.e., users, compute jobs, cluster nodes, …
- Object-Centric Analysis of HPC Clusters (Aaron Küsters)
- Object-centric project inspired by work on previous case-centric analysis (SLURMminer)
- Extracting OCELs from RWTH’s HPC cluster for longer timeframes (i.e., >~30 days)
- Analysis of extracted OCEL using object-centric Process Mining techniques (OCPQ, OC-DECLARE, PM4Py) to identify general process behavior, interesting patterns, …
- Enabling analysis using graphical user interface of developed OCPQ tool (ocpq.aarkue.eu/)
- Parallelization of Process Mining Algorithms (Aaron Küsters)
- Implement (object-centric) process mining techniques in a parallelized manner, allowing scaling them on HPC hardware for larger or more complex data.
- Already implemented parallelized algorithms: OCPQ Query Engine (see ocpq.aarkue.eu/ and github.com/aarkue/ocpq), OC-DECLARE constraint mining (github.com/aarkue/rust4pm), Alpha+++ Discovery (github.com/aarkue/rust4pm)
Competencies
- Machine Learning & Deep Learning
- Metadata Management
- Automation of Data Engineering Tasks
- Process Mining
- Simplified Access to Data Repositories
- Support Data Transfers
- Federated & Distributed Learning
- AutoML
- Storage Space Applications
Activities
- Tools: FEATHERS, Interactive HPO (IHPO), SlurmMiner
- Coscine – Research Data Management Platform
- Supporting Migrations of Storage Systems
- Focus group: RDM in NHR
- Cooperations inside and outside of NHR
- Training courses on Machine Learning and Deep Learning, AutoML, Process Mining, Federated- and Distributed Learning
Support activities
- JARDS as source of project specific metadata and a common entry point to request resources (computing time and storage together with NFDI4Ing)
- Coscine an integration platform that allows services such as the archive, research data storage (RDS.NRW) and GitLab, but also external storages to be linked with one another at project level and stored with metadata
- Support in overcoming data size/quality/privacy issues
- Assistance in specific infrastructural challenges
- Support for scientists with Machine Learning or Process Mining problems applied to their specific research field
Teaching activities:
- “Data Literacy for All” (hub with links to existing good online courses, best practices, online exercises, ….): https://data-ai-literacy.ml/
- Hackathons with tools for data engineering
- Research Data Management with GitLab
- Learning material for Process Mining & Machine Learning
Gallery
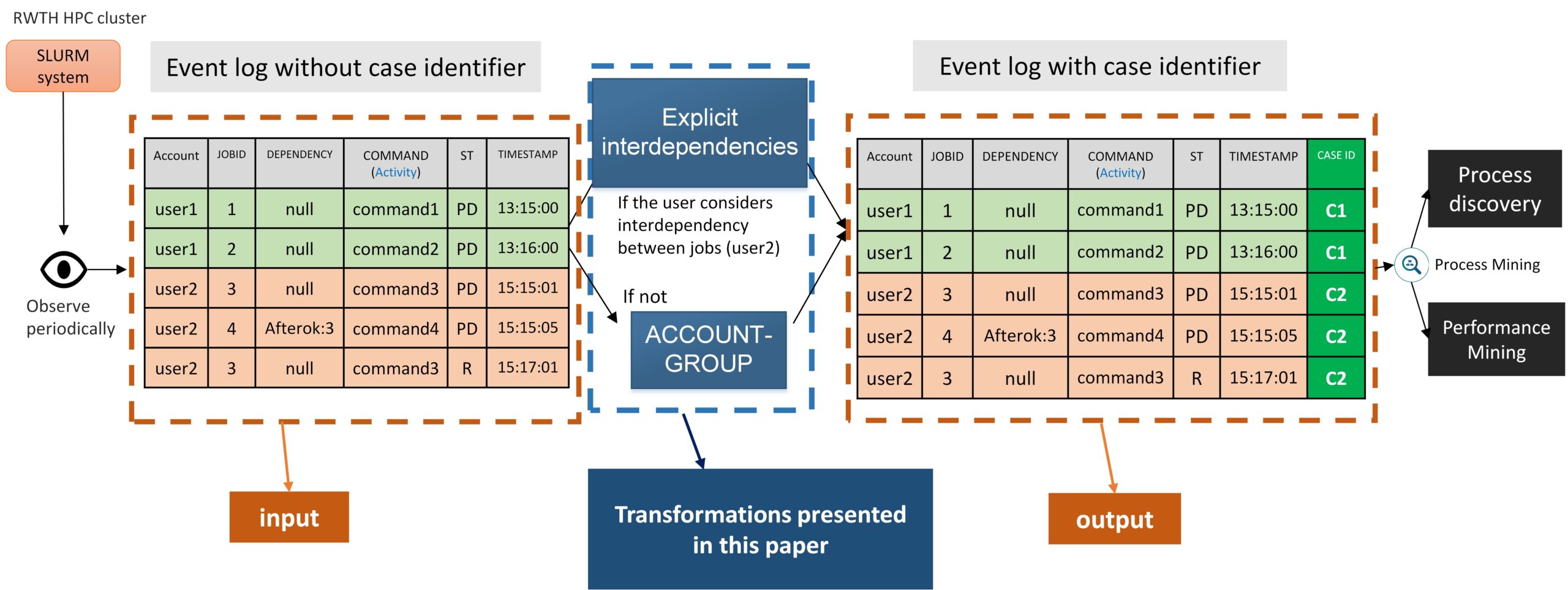 SLURMminer
SLURMminer  A bi-level neural architecture search algorithm for neural probabilistic models with the goal to predict time series with uncertainty estimates. Paper: https://openreview.net/pdf?id=AaPhnfFQYn
A bi-level neural architecture search algorithm for neural probabilistic models with the goal to predict time series with uncertainty estimates. Paper: https://openreview.net/pdf?id=AaPhnfFQYn  FEATHERS – a framework for automatic optimization of neural architectures and hyperparameters
FEATHERS – a framework for automatic optimization of neural architectures and hyperparameters  IBO-HPC – a new hyperparameter optimization (HPO) algorithm
IBO-HPC – a new hyperparameter optimization (HPO) algorithm  Currently the largest open collection of real-world relational databases. The Code & Data are Open Source: ~325 Downloads since December 2024. A spotlight paper at NeurIPS 2024 (A* ML conference).
Currently the largest open collection of real-world relational databases. The Code & Data are Open Source: ~325 Downloads since December 2024. A spotlight paper at NeurIPS 2024 (A* ML conference).  Enabling the research data management platform Coscine for HPC use cases. It supports researchers throughout the entire research data life cycle. Currently more than 3300 users and more than 4750 projects
Enabling the research data management platform Coscine for HPC use cases. It supports researchers throughout the entire research data life cycle. Currently more than 3300 users and more than 4750 projects 

CSG ML & DS Training from October 15, 2025: “Analyzing HPC Clusters Using Object-Centric Process Mining”
Members

Prof. Dr. Carsten Binnig
TU Darmstadt

Jan-Micha Bodensohn
TU Darmstadt
Manuel Brack
TU Darmstadt

Prof. Dr. Kristian Kersting
TU Darmstadt

Prof. Dr. Bastian Leibe
RWTH Aachen University

Aaron Küsters
RWTH Aachen University
Rudo Mtengwa
RWTH Aachen University

Prof. Dr. Matthias Müller
RWTH Aachen University

Marcel Nellesen
RWTH Aachen University

Viktor Pfanschilling
TU Darmstadt

Jonas Seng
TU Darmstadt

Liane Vogel
TU Darmstadt

Prof. Dr. Wil van der Aalst
RWTH Aachen University
Project partners
Publications
2025
- OC-DECLARE: Discovering Object-Centric Declarative Patterns with Synchronization
https://link.springer.com/chapter/10.1007/978-3-032-02867-9_11
Küsters, A., van der Aalst, W.M.P. (2026). OC-DECLARE: Discovering Object-Centric Declarative Patterns with Synchronization. In: Senderovich, A., Cabanillas, C., Vanderfeesten, I., A. Reijers, H. (eds) Business Process Management. BPM 2025. Lecture Notes in Computer Science, vol 16044. Springer, Cham. https://doi.org/10.1007/978-3-032-02867-9_11 - OCPQ: Object-Centric Process Querying and Constraints
https://link.springer.com/chapter/10.1007/978-3-031-92474-3_23
2024
- Learning Large DAGs is Harder Than You Think (Jonas Seng, Matej Zečević, Devendra Singh Dhami, Kristian Kersting), ICLR 24
- Bi-Level One-Shot Architecture Search for Probabilistic Time Series Forecasting (Jonas Seng, Fabian Kalter, Zhongjie Yu, Fabrizio Ventola, Kristian Kersting), AutoML Conf 24
- Psinet: Efficient Causal Modelling at Scale (Florian Busch, Moritz Willig, Jonas Seng, Kristian Kersting, Devendra Singh Dhami), PGM 24
- Demonstrating CAESURA: Language Models as Multi-Modal Query Planners. (Matthias Urban, Carsten Binnig), SIGMOD’24 Demo Track
- Rethinking Table Retrieval from Data Lakes. (Jan-Micha Bodensohn, Carsten Binnig), aiDM’24@SIGMOD’24
- LLMs for Data Engineering on Enterprise Data. (Jan-Micha Bodensohn, Ulf Brackmann, Liane Vogel, Matthias Urban, Anupam Sanghi, Carsten Binnig), TaDA@VLDB’24
2023
- WannaDB: Ad-hoc SQL Queries over Text Collections. (Benjamin Hättasch, Jan-Micha Bodensohn, Liane Vogel, Matthias Urban, Carsten Binnig), Datenbanksysteme für Business, Technologie und Web (BTW 2023)
- Carrots and Sticks: Motivating with Storage for Good RDM (Ilona Lang, Marcel Nellesen, Lukas Bossert, Marius Politze)
- RDM Platform Coscine – FAIR play integrated right from the start (Ilona Lang, Marcel Nellesen, Marius Politze)
- Treatment Effect Estimation to Guide Model Optimization in Continual Learning (Jonas Seng, Florian P. Busch, Matej Zečević, Moritz Willig), Continual Causality Bridge Program (@AAAI 2023)
- Causal Concept Identification in Open World Environments, (Moritz Willig, Matej Zečević, Jonas Seng, Florian P. Busch), Continual Causality Bridge Program (@AAAI 2023)
- SLURMminer: A Tool for SLURM System Analysis with Process Mining, (Zahra Sadeghibogar, Alessandro Berti, Marco Pegoraro, Wil MP van der Aalst), BPM 23
2022
- Towards Foundation Models for Relational Databases. (Liane Vogel, Benjamin Hilprecht, Carsten Binnig), TRL@NeurIPS 2022
2021
- It’s AI Match: A Two-Step Approach for Schema Matching Using Embeddings. (Benjamin Hättasch, Michael Truong-Ngoc, Andreas Schmidt, Carsten Binnig), AIDB@VLDB 2020
- Küsters, A., van der Aalst, W.M.P. (2025). OCPQ: Object-Centric Process Querying and Constraints. In: Grabis, J., Vos, T.E.J., Escalona, M.J., Pastor, O. (eds) Research Challenges in Information Science. RCIS 2025. Lecture Notes in Business Information Processing, vol 547. Springer, Cham. https://doi.org/10.1007/978-3-031-92474-3_23
- ELEET: Efficient Learned Query Execution over Text and Tables (Matthias Urban, Carsten Binnig), VLDB’25
- Towards Complex Table Question Answering Over Tabular Data Lakes (Daniela Risis, Jan-Micha Bodensohn, Matthias Urban, Carsten Binnig ), DE4DS@BTW’25
- Hyperparameter Optimization via Interacting with Probabilistic Circuits (Jonas Seng, Fabrizio Ventola, Zhongjie Yu, Kristian Kersting), UAI 24 (TPM Workshop)
- FEATHERS: Federated Architecture and Hyperparameter Search (Jonas Seng, Pooja Prasad, Devendra Singh Dhami, Martin Mundt, Kristian Kersting), AutoML Conf 24 (Workshop)
- Automating Enterprise Data Engineering with LLMs. (Jan-Micha Bodensohn, Ulf Brackmann, Liane Vogel, Anupam Sanghi, Carsten Binnig ), TRL@NeurIPS’24
- WikiDBs: A Large-Scale Corpus Of Relational Databases From Wikidata. (
Liane Vogel, Jan-Micha Bodensohn, Carsten Binnig), NeurIPS’24 Datasets&Benchmarks Track - CAESURA: Language Models as Multi-Modal Query Planners. (Matthias Urban, Carsten Binnig), CIDR’24
- Continually Updating Neural Causal Models, (Florian P. Busch, Jonas Seng, Moritz Willig, Matej Zečević), Continual Causality Bridge Program (@AAAI 2023)
- Continual Causal Abstractions, (Matej Zečević, Moritz Willig, Florian P. Busch, Jonas Seng), Continual Causality Bridge Program (@AAAI 2023)
- Exploring SLURM Logs through Process Mining: Insights into Scientific Workflows, (Zahra Sadeghibogar, Alessandro Berti, Marco Pegoraro, Wil MP van der Aalst), BPM 23
- OmniscientDB: A Large Language Model-Augmented DBMS That Knows What Other DBMSs Do Not Know (Matthias Urban, Duc Dat Nguyen and Carsten Binnig), AIDM@SIGMOD
- WikiDBs: A corpus of relational databases from wikidata (Liane Vogel, Carsten Binnig), TADA@VLDB 2023
- ScaleStore: A Fast and Cost-Efficient Storage Engine using DRAM, NVMe, and RDMA. (Tobias Ziegler, Carsten Binnig, Viktor Leis), SIGMOD 2022
- ASET: Ad-hoc Structured Exploration of Text Collections. (Benjamin Hättasch, Jan-Micha Bodensohn, Carsten Binnig), AIDB@VLDB 2021